Python Script That Reads in the Contents and Stores the Data in a Container
Data structures are the fundamental constructs effectually which y'all build your programs. Each data structure provides a particular way of organizing data so it tin be accessed efficiently, depending on your use case. Python ships with an extensive ready of data structures in its standard library.
However, Python's naming convention doesn't provide the same level of clarity that you'll notice in other languages. In Java, a list isn't just a list—it's either a LinkedList or an ArrayList. Non then in Python. Even experienced Python developers sometimes wonder whether the built-in list blazon is implemented as a linked listing or a dynamic array.
In this tutorial, you'll acquire:
- Which common abstract data types are built into the Python standard library
- How the most mutual abstruse data types map to Python'south naming scheme
- How to put abstract data types to practical use in various algorithms
Dictionaries, Maps, and Hash Tables
In Python, dictionaries (or dicts for curt) are a fundamental data structure. Dicts shop an capricious number of objects, each identified by a unique dictionary key.
Dictionaries are likewise often chosen maps, hashmaps, lookup tables, or associative arrays. They allow for the efficient lookup, insertion, and deletion of whatsoever object associated with a given key.
Phone books make a decent real-world analog for dictionary objects. They allow yous to apace retrieve the information (telephone number) associated with a given primal (a person's proper noun). Instead of having to read a phone book forepart to back to notice someone'due south number, you lot can jump more or less directly to a name and expect up the associated information.
This analogy breaks down somewhat when it comes to how the information is organized to allow for fast lookups. But the central performance characteristics concord. Dictionaries allow you to apace observe the information associated with a given cardinal.
Dictionaries are one of the most important and frequently used information structures in computer scientific discipline. So, how does Python handle dictionaries? Let's have a tour of the lexicon implementations bachelor in cadre Python and the Python standard library.
dict: Your Get-To Dictionary
Because dictionaries are so important, Python features a robust dictionary implementation that's built directly into the core language: the dict data type.
Python also provides some useful syntactic sugar for working with dictionaries in your programs. For example, the curly-caryatid ({ }) dictionary expression syntax and dictionary comprehensions allow you to conveniently define new dictionary objects:
>>>
>>> phonebook = { ... "bob" : 7387 , ... "alice" : 3719 , ... "jack" : 7052 , ... } >>> squares = { x : ten * x for ten in range ( six )} >>> phonebook [ "alice" ] 3719 >>> squares {0: 0, 1: 1, 2: iv, three: ix, four: 16, v: 25} There are some restrictions on which objects can be used as valid keys.
Python's dictionaries are indexed by keys that can be of any hashable type. A hashable object has a hash value that never changes during its lifetime (see __hash__), and information technology can be compared to other objects (see __eq__). Hashable objects that compare every bit equal must have the same hash value.
Immutable types similar strings and numbers are hashable and piece of work well as dictionary keys. Yous tin can also use tuple objects as dictionary keys as long equally they contain but hashable types themselves.
For about utilize cases, Python'due south built-in dictionary implementation will do everything you need. Dictionaries are highly optimized and underlie many parts of the language. For example, course attributes and variables in a stack frame are both stored internally in dictionaries.
Python dictionaries are based on a well-tested and finely tuned hash tabular array implementation that provides the performance characteristics you'd wait: O(ane) time complication for lookup, insert, update, and delete operations in the average instance.
There's trivial reason not to use the standard dict implementation included with Python. However, specialized tertiary-political party lexicon implementations be, such equally skip lists or B-tree–based dictionaries.
Besides plain dict objects, Python'due south standard library also includes a number of specialized lexicon implementations. These specialized dictionaries are all based on the built-in dictionary class (and share its performance characteristics) but likewise include some additional convenience features.
Let'south take a look at them.
collections.OrderedDict: Remember the Insertion Order of Keys
Python includes a specialized dict subclass that remembers the insertion lodge of keys added to it: collections.OrderedDict.
While standard dict instances preserve the insertion society of keys in CPython 3.half dozen and above, this was simply a side effect of the CPython implementation and was non defined in the language spec until Python 3.seven. So, if fundamental order is important for your algorithm to work, and so it's all-time to communicate this clearly by explicitly using the OrderedDict class:
>>>
>>> import collections >>> d = collections . OrderedDict ( one = 1 , two = 2 , three = 3 ) >>> d OrderedDict([('1', i), ('two', 2), ('three', 3)]) >>> d [ "four" ] = 4 >>> d OrderedDict([('i', 1), ('two', 2), ('three', iii), ('four', 4)]) >>> d . keys () odict_keys(['one', 'ii', 'three', 'four']) Until Python 3.viii, you couldn't iterate over dictionary items in reverse guild using reversed(). Simply OrderedDict instances offered that functionality. Even in Python 3.8, dict and OrderedDict objects aren't exactly the same. OrderedDict instances take a .move_to_end() method that is unavailable on plain dict instance, as well as a more customizable .popitem() method than the one plain dict instances.
collections.defaultdict: Return Default Values for Missing Keys
The defaultdict course is some other dictionary subclass that accepts a callable in its constructor whose return value volition be used if a requested key cannot exist found.
This can save yous some typing and make your intentions clearer as compared to using get() or catching a KeyError exception in regular dictionaries:
>>>
>>> from collections import defaultdict >>> dd = defaultdict ( list ) >>> # Accessing a missing key creates it and >>> # initializes it using the default factory, >>> # i.e. list() in this instance: >>> dd [ "dogs" ] . append ( "Rufus" ) >>> dd [ "dogs" ] . append ( "Kathrin" ) >>> dd [ "dogs" ] . append ( "Mr Sniffles" ) >>> dd [ "dogs" ] ['Rufus', 'Kathrin', 'Mr Sniffles'] collections.ChainMap: Search Multiple Dictionaries as a Single Mapping
The collections.ChainMap data construction groups multiple dictionaries into a single mapping. Lookups search the underlying mappings one by 1 until a key is found. Insertions, updates, and deletions only affect the first mapping added to the chain:
>>>
>>> from collections import ChainMap >>> dict1 = { "ane" : 1 , "two" : 2 } >>> dict2 = { "iii" : 3 , "four" : 4 } >>> chain = ChainMap ( dict1 , dict2 ) >>> chain ChainMap({'ane': 1, 'two': 2}, {'three': iii, 'four': iv}) >>> # ChainMap searches each collection in the chain >>> # from left to right until it finds the key (or fails): >>> chain [ "three" ] three >>> chain [ "one" ] 1 >>> chain [ "missing" ] Traceback (nearly recent call last): File "<stdin>", line 1, in <module> KeyError: 'missing' types.MappingProxyType: A Wrapper for Making Read-Only Dictionaries
MappingProxyType is a wrapper effectually a standard dictionary that provides a read-simply view into the wrapped dictionary'south data. This grade was added in Python 3.three and can exist used to create immutable proxy versions of dictionaries.
MappingProxyType can be helpful if, for instance, you'd like to return a dictionary carrying internal land from a form or module while discouraging write admission to this object. Using MappingProxyType allows you lot to put these restrictions in place without outset having to create a full copy of the dictionary:
>>>
>>> from types import MappingProxyType >>> writable = { "one" : 1 , "two" : 2 } >>> read_only = MappingProxyType ( writable ) >>> # The proxy is read-only: >>> read_only [ "ane" ] 1 >>> read_only [ "one" ] = 23 Traceback (virtually recent phone call terminal): File "<stdin>", line 1, in <module> TypeError: 'mappingproxy' object does not support item consignment >>> # Updates to the original are reflected in the proxy: >>> writable [ "i" ] = 42 >>> read_only mappingproxy({'one': 42, 'two': two}) Dictionaries in Python: Summary
All the Python dictionary implementations listed in this tutorial are valid implementations that are built into the Python standard library.
If you're looking for a general recommendation on which mapping type to employ in your programs, I'd point you lot to the built-in dict information type. It's a versatile and optimized hash table implementation that's built straight into the core language.
I would recommend that y'all use one of the other data types listed here just if you have special requirements that go across what's provided by dict.
All the implementations are valid options, but your code volition exist clearer and easier to maintain if it relies on standard Python dictionaries well-nigh of the time.
Array Data Structures
An assortment is a fundamental information construction available in nearly programming languages, and it has a wide range of uses across different algorithms.
In this section, y'all'll have a await at array implementations in Python that use merely core language features or functionality that's included in the Python standard library. You'll see the strengths and weaknesses of each approach and so you can decide which implementation is right for your utilize case.
Merely before nosotros jump in, allow's cover some of the basics outset. How do arrays work, and what are they used for? Arrays consist of stock-still-size information records that allow each chemical element to be efficiently located based on its index:
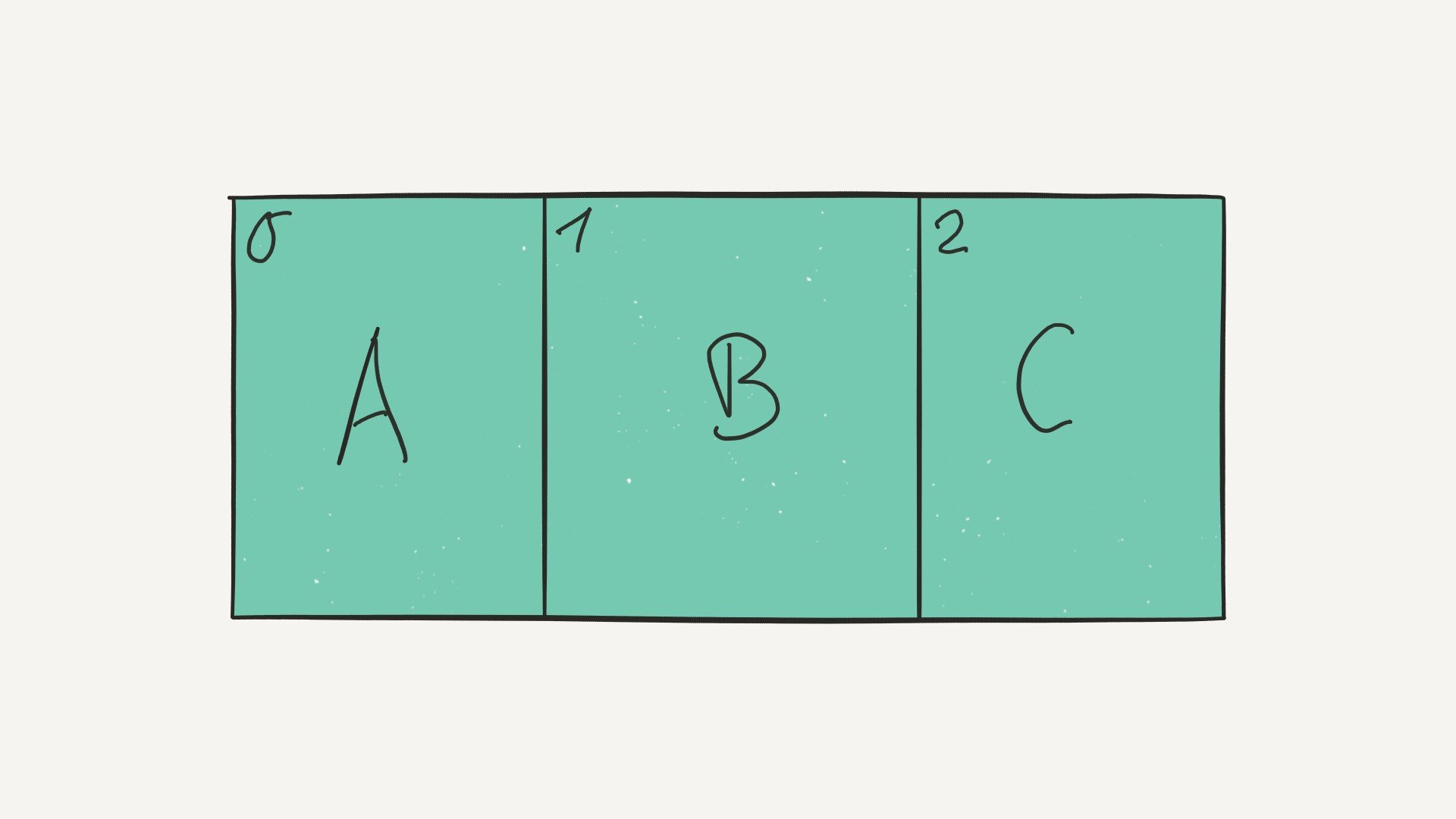
Because arrays store information in adjoining blocks of retentivity, they're considered contiguous data structures (as opposed to linked data structures like linked lists, for example).
A existent-world analogy for an assortment data structure is a parking lot. You lot can await at the parking lot as a whole and treat it every bit a single object, but within the lot there are parking spots indexed by a unique number. Parking spots are containers for vehicles—each parking spot can either be empty or take a car, a motorbike, or some other vehicle parked on it.
Only not all parking lots are the same. Some parking lots may exist restricted to only 1 blazon of vehicle. For case, a motor domicile parking lot wouldn't let bikes to be parked on it. A restricted parking lot corresponds to a typed array information structure that allows only elements that have the aforementioned data type stored in them.
Performance-wise, it's very fast to wait up an element contained in an array given the chemical element's index. A proper array implementation guarantees a constant O(1) access time for this case.
Python includes several array-similar data structures in its standard library that each take slightly dissimilar characteristics. Allow's take a look.
list: Mutable Dynamic Arrays
Lists are a part of the core Python language. Despite their name, Python'south lists are implemented as dynamic arrays behind the scenes.
This means a list allows elements to exist added or removed, and the list volition automatically adjust the backing store that holds these elements past allocating or releasing memory.
Python lists can hold arbitrary elements—everything is an object in Python, including functions. Therefore, you can mix and match different kinds of information types and store them all in a single listing.
This tin can be a powerful feature, but the downside is that supporting multiple data types at the same time means that data is generally less tightly packed. As a result, the whole structure takes up more space:
>>>
>>> arr = [ "one" , "ii" , "3" ] >>> arr [ 0 ] '1' >>> # Lists have a prissy repr: >>> arr ['one', 'two', 'three'] >>> # Lists are mutable: >>> arr [ ane ] = "hello" >>> arr ['1', 'hello', 'three'] >>> del arr [ ane ] >>> arr ['ane', 'three'] >>> # Lists can hold arbitrary data types: >>> arr . suspend ( 23 ) >>> arr ['one', 'iii', 23] tuple: Immutable Containers
Just similar lists, tuples are part of the Python core language. Unlike lists, however, Python'south tuple objects are immutable. This ways elements can't be added or removed dynamically—all elements in a tuple must be defined at creation time.
Tuples are some other data structure that tin concur elements of capricious data types. Having this flexibility is powerful, just again, it too means that data is less tightly packed than information technology would exist in a typed assortment:
>>>
>>> arr = ( "one" , "two" , "3" ) >>> arr [ 0 ] 'one' >>> # Tuples have a nice repr: >>> arr ('ane', 'ii', 'three') >>> # Tuples are immutable: >>> arr [ 1 ] = "hello" Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'tuple' object does non support item assignment >>> del arr [ ane ] Traceback (most recent phone call final): File "<stdin>", line one, in <module> TypeError: 'tuple' object doesn't support item deletion >>> # Tuples tin can hold arbitrary information types: >>> # (Adding elements creates a copy of the tuple) >>> arr + ( 23 ,) ('ane', 'two', 'three', 23) array.assortment: Basic Typed Arrays
Python's array module provides space-efficient storage of basic C-manner data types like bytes, 32-bit integers, floating-signal numbers, and then on.
Arrays created with the array.array class are mutable and behave similarly to lists except for one important difference: they're typed arrays constrained to a unmarried data type.
Because of this constraint, assortment.assortment objects with many elements are more space efficient than lists and tuples. The elements stored in them are tightly packed, and this tin exist useful if you demand to store many elements of the same type.
As well, arrays support many of the same methods equally regular lists, and you lot might be able to use them equally a drop-in replacement without requiring other changes to your application code.
>>>
>>> import array >>> arr = assortment . array ( "f" , ( 1.0 , i.5 , two.0 , 2.5 )) >>> arr [ 1 ] ane.5 >>> # Arrays have a squeamish repr: >>> arr assortment('f', [1.0, i.5, 2.0, ii.5]) >>> # Arrays are mutable: >>> arr [ 1 ] = 23.0 >>> arr array('f', [one.0, 23.0, 2.0, 2.5]) >>> del arr [ i ] >>> arr assortment('f', [1.0, 2.0, two.5]) >>> arr . suspend ( 42.0 ) >>> arr array('f', [1.0, ii.0, two.v, 42.0]) >>> # Arrays are "typed": >>> arr [ 1 ] = "hello" Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: must be existent number, not str str: Immutable Arrays of Unicode Characters
Python 3.10 uses str objects to store textual data every bit immutable sequences of Unicode characters. Practically speaking, that means a str is an immutable array of characters. Oddly enough, it's besides a recursive information structure—each character in a string is itself a str object of length 1.
Cord objects are space efficient because they're tightly packed and they specialize in a unmarried data blazon. If you're storing Unicode text, then you should use a string.
Considering strings are immutable in Python, modifying a cord requires creating a modified copy. The closest equivalent to a mutable string is storing individual characters within a list:
>>>
>>> arr = "abcd" >>> arr [ i ] 'b' >>> arr 'abcd' >>> # Strings are immutable: >>> arr [ 1 ] = "e" Traceback (nigh recent call concluding): File "<stdin>", line 1, in <module> TypeError: 'str' object does not support item assignment >>> del arr [ 1 ] Traceback (most contempo call final): File "<stdin>", line 1, in <module> TypeError: 'str' object doesn't support detail deletion >>> # Strings tin can exist unpacked into a listing to >>> # become a mutable representation: >>> list ( "abcd" ) ['a', 'b', 'c', 'd'] >>> "" . join ( listing ( "abcd" )) 'abcd' >>> # Strings are recursive data structures: >>> blazon ( "abc" ) "<class 'str'>" >>> type ( "abc" [ 0 ]) "<class 'str'>" bytes: Immutable Arrays of Single Bytes
bytes objects are immutable sequences of single bytes, or integers in the range 0 ≤ x ≤ 255. Conceptually, bytes objects are similar to str objects, and you can also call up of them every bit immutable arrays of bytes.
Similar strings, bytes have their own literal syntax for creating objects and are space efficient. bytes objects are immutable, simply unlike strings, there'south a dedicated mutable byte assortment data blazon called bytearray that they can be unpacked into:
>>>
>>> arr = bytes (( 0 , i , 2 , three )) >>> arr [ one ] 1 >>> # Bytes literals have their ain syntax: >>> arr b'\x00\x01\x02\x03' >>> arr = b " \x00\x01\x02\x03 " >>> # Only valid `bytes` are immune: >>> bytes (( 0 , 300 )) Traceback (near recent phone call final): File "<stdin>", line 1, in <module> ValueError: bytes must be in range(0, 256) >>> # Bytes are immutable: >>> arr [ 1 ] = 23 Traceback (most recent phone call final): File "<stdin>", line 1, in <module> TypeError: 'bytes' object does non support item assignment >>> del arr [ 1 ] Traceback (most recent call concluding): File "<stdin>", line i, in <module> TypeError: 'bytes' object doesn't back up particular deletion bytearray: Mutable Arrays of Single Bytes
The bytearray type is a mutable sequence of integers in the range 0 ≤ x ≤ 255. The bytearray object is closely related to the bytes object, with the main difference being that a bytearray can exist modified freely—you can overwrite elements, remove existing elements, or add together new ones. The bytearray object will grow and compress appropriately.
A bytearray tin be converted dorsum into immutable bytes objects, merely this involves copying the stored data in full—a slow performance taking O(northward) fourth dimension:
>>>
>>> arr = bytearray (( 0 , 1 , ii , 3 )) >>> arr [ i ] 1 >>> # The bytearray repr: >>> arr bytearray(b'\x00\x01\x02\x03') >>> # Bytearrays are mutable: >>> arr [ 1 ] = 23 >>> arr bytearray(b'\x00\x17\x02\x03') >>> arr [ 1 ] 23 >>> # Bytearrays can grow and shrink in size: >>> del arr [ 1 ] >>> arr bytearray(b'\x00\x02\x03') >>> arr . append ( 42 ) >>> arr bytearray(b'\x00\x02\x03*') >>> # Bytearrays tin only hold `bytes` >>> # (integers in the range 0 <= x <= 255) >>> arr [ 1 ] = "hello" Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'str' object cannot exist interpreted equally an integer >>> arr [ i ] = 300 Traceback (most recent telephone call concluding): File "<stdin>", line 1, in <module> ValueError: byte must be in range(0, 256) >>> # Bytearrays can be converted back into bytes objects: >>> # (This will copy the information) >>> bytes ( arr ) b'\x00\x02\x03*' Arrays in Python: Summary
There are a number of born data structures you lot can choose from when it comes to implementing arrays in Python. In this section, you lot've focused on cadre language features and data structures included in the standard library.
If yous're willing to go beyond the Python standard library, then third-party packages like NumPy and pandas offer a wide range of fast array implementations for scientific calculating and data science.
If you want to restrict yourself to the assortment data structures included with Python, then here are a few guidelines:
-
If you need to store capricious objects, potentially with mixed data types, then use a
listor atuple, depending on whether or non you want an immutable data structure. -
If you have numeric (integer or floating-point) data and tight packing and performance is of import, and so endeavour out
array.array. -
If you have textual data represented as Unicode characters, then apply Python's built-in
str. If you need a mutable string-like information structure, then utilise alistingof characters. -
If yous want to store a face-to-face block of bytes, then utilize the immutable
bytestype or abytearrayif you need a mutable data structure.
In nearly cases, I like to beginning out with a simple listing. I'll simply specialize later on on if functioning or storage space becomes an issue. Most of the time, using a general-purpose array data structure similar list gives you the fastest development speed and the virtually programming convenience.
I've found that this is commonly much more important in the beginning than trying to squeeze out every last driblet of functioning right from the offset.
Records, Structs, and Information Transfer Objects
Compared to arrays, record information structures provide a fixed number of fields. Each field can have a name and may as well have a unlike blazon.
In this section, you lot'll come across how to implement records, structs, and evidently old data objects in Python using only congenital-in information types and classes from the standard library.
Python offers several data types that you can utilize to implement records, structs, and information transfer objects. In this section, you'll get a quick look at each implementation and its unique characteristics. At the end, yous'll detect a summary and a controlling guide that volition help you make your own picks.
Alright, permit's get started!
dict: Simple Information Objects
As mentioned previously, Python dictionaries store an arbitrary number of objects, each identified by a unique fundamental. Dictionaries are also often called maps or associative arrays and allow for efficient lookup, insertion, and deletion of any object associated with a given key.
Using dictionaries as a record data type or data object in Python is possible. Dictionaries are easy to create in Python every bit they take their own syntactic saccharide congenital into the language in the form of dictionary literals. The lexicon syntax is concise and quite convenient to type.
Data objects created using dictionaries are mutable, and there's little protection confronting misspelled field names every bit fields can be added and removed freely at whatever time. Both of these properties tin introduce surprising bugs, and at that place'south ever a merchandise-off to be made between convenience and error resilience:
>>>
>>> car1 = { ... "color" : "scarlet" , ... "mileage" : 3812.4 , ... "automatic" : True , ... } >>> car2 = { ... "color" : "blue" , ... "mileage" : 40231 , ... "automated" : False , ... } >>> # Dicts have a nice repr: >>> car2 {'color': 'blue', 'automatic': False, 'mileage': 40231} >>> # Get mileage: >>> car2 [ "mileage" ] 40231 >>> # Dicts are mutable: >>> car2 [ "mileage" ] = 12 >>> car2 [ "windshield" ] = "broken" >>> car2 {'windshield': 'cleaved', 'color': 'blueish', 'automated': False, 'mileage': 12} >>> # No protection against wrong field names, >>> # or missing/extra fields: >>> car3 = { ... "colr" : "dark-green" , ... "automatic" : Imitation , ... "windshield" : "broken" , ... } tuple: Immutable Groups of Objects
Python's tuples are a straightforward information structure for grouping capricious objects. Tuples are immutable—they tin can't be modified in one case they've been created.
Operation-wise, tuples accept up slightly less memory than lists in CPython, and they're as well faster to construct.
As you can run across in the bytecode disassembly below, amalgam a tuple constant takes a single LOAD_CONST opcode, while constructing a listing object with the same contents requires several more than operations:
>>>
>>> import dis >>> dis . dis ( compile ( "(23, 'a', 'b', 'c')" , "" , "eval" )) 0 LOAD_CONST 4 ((23, "a", "b", "c")) three RETURN_VALUE >>> dis . dis ( compile ( "[23, 'a', 'b', 'c']" , "" , "eval" )) 0 LOAD_CONST 0 (23) 3 LOAD_CONST one ('a') 6 LOAD_CONST 2 ('b') 9 LOAD_CONST 3 ('c') 12 BUILD_LIST 4 15 RETURN_VALUE However, you shouldn't place too much emphasis on these differences. In practice, the functioning departure will often exist negligible, and trying to squeeze extra performance out of a programme by switching from lists to tuples will likely be the wrong approach.
A potential downside of plain tuples is that the data yous store in them can only be pulled out past accessing information technology through integer indexes. You lot can't give names to individual properties stored in a tuple. This tin can impact lawmaking readability.
Also, a tuple is always an ad-hoc construction: it's difficult to ensure that ii tuples have the same number of fields and the same properties stored in them.
This makes it like shooting fish in a barrel to innovate slip-of-the-listen bugs, such as mixing up the field society. Therefore, I would recommend that yous keep the number of fields stored in a tuple equally low as possible:
>>>
>>> # Fields: color, mileage, automatic >>> car1 = ( "red" , 3812.4 , Truthful ) >>> car2 = ( "blueish" , 40231.0 , False ) >>> # Tuple instances accept a nice repr: >>> car1 ('crimson', 3812.4, True) >>> car2 ('bluish', 40231.0, False) >>> # Get mileage: >>> car2 [ 1 ] 40231.0 >>> # Tuples are immutable: >>> car2 [ i ] = 12 Traceback (virtually recent call concluding): File "<stdin>", line 1, in <module> TypeError: 'tuple' object does not support item consignment >>> # No protection against missing or actress fields >>> # or a wrong order: >>> car3 = ( 3431.5 , "green" , True , "silver" ) Write a Custom Form: More Work, More than Command
Classes let you to ascertain reusable blueprints for information objects to ensure each object provides the same set of fields.
Using regular Python classes as record information types is feasible, only it too takes manual work to get the convenience features of other implementations. For example, adding new fields to the __init__ constructor is verbose and takes time.
Likewise, the default string representation for objects instantiated from custom classes isn't very helpful. To gear up that, yous may have to add your own __repr__ method, which again is normally quite verbose and must exist updated each time you add a new field.
Fields stored on classes are mutable, and new fields can be added freely, which you may or may not like. Information technology'due south possible to provide more admission control and to create read-only fields using the @property decorator, merely once more, this requires writing more than mucilage code.
Writing a custom class is a great pick whenever you'd like to add business logic and behavior to your record objects using methods. However, this means that these objects are technically no longer evidently information objects:
>>>
>>> form Car : ... def __init__ ( self , color , mileage , automatic ): ... self . color = color ... self . mileage = mileage ... self . automatic = automatic ... >>> car1 = Car ( "cherry" , 3812.four , True ) >>> car2 = Car ( "blue" , 40231.0 , False ) >>> # Get the mileage: >>> car2 . mileage 40231.0 >>> # Classes are mutable: >>> car2 . mileage = 12 >>> car2 . windshield = "broken" >>> # String representation is non very useful >>> # (must add a manually written __repr__ method): >>> car1 <Car object at 0x1081e69e8> dataclasses.dataclass: Python 3.7+ Information Classes
Data classes are bachelor in Python iii.7 and above. They provide an fantabulous alternative to defining your own data storage classes from scratch.
By writing a information class instead of a plain Python grade, your object instances go a few useful features out of the box that will save you lot some typing and manual implementation work:
- The syntax for defining case variables is shorter, since you don't need to implement the
.__init__()method. - Instances of your data class automatically become nice-looking string representation via an motorcar-generated
.__repr__()method. - Case variables accept type annotations, making your data grade self-documenting to a caste. Keep in mind that type annotations are but hints that are not enforced without a carve up type-checking tool.
Data classes are typically created using the @dataclass decorator, as you lot'll see in the code example below:
>>>
>>> from dataclasses import dataclass >>> @dataclass ... class Car : ... color : str ... mileage : float ... automated : bool ... >>> car1 = Car ( "red" , 3812.4 , True ) >>> # Instances have a nice repr: >>> car1 Car(colour='red', mileage=3812.4, automated=True) >>> # Accessing fields: >>> car1 . mileage 3812.4 >>> # Fields are mutable: >>> car1 . mileage = 12 >>> car1 . windshield = "broken" >>> # Type annotations are not enforced without >>> # a separate blazon checking tool like mypy: >>> Motorcar ( "red" , "NOT_A_FLOAT" , 99 ) Car(color='red', mileage='NOT_A_FLOAT', automatic=99) To learn more than about Python data classes, cheque out the The Ultimate Guide to Information Classes in Python iii.7.
collections.namedtuple: Convenient Information Objects
The namedtuple class available in Python 2.six+ provides an extension of the built-in tuple data type. Similar to defining a custom form, using namedtuple allows you to ascertain reusable blueprints for your records that ensure the correct field names are used.
namedtuple objects are immutable, just like regular tuples. This means you can't add new fields or modify existing fields afterwards the namedtuple case is created.
Besides that, namedtuple objects are, well . . . named tuples. Each object stored in them can be accessed through a unique identifier. This frees you from having to remember integer indexes or resort to workarounds like defining integer constants as mnemonics for your indexes.
namedtuple objects are implemented as regular Python classes internally. When it comes to retentivity usage, they're also better than regular classes and just as memory efficient every bit regular tuples:
>>>
>>> from collections import namedtuple >>> from sys import getsizeof >>> p1 = namedtuple ( "Signal" , "x y z" )( 1 , two , 3 ) >>> p2 = ( ane , 2 , three ) >>> getsizeof ( p1 ) 64 >>> getsizeof ( p2 ) 64 namedtuple objects can be an easy way to clean up your code and make it more readable past enforcing a better construction for your data.
I find that going from ad-hoc information types like dictionaries with a stock-still format to namedtuple objects helps me to limited the intent of my code more than clearly. Often when I apply this refactoring, I magically come with a amend solution for the problem I'm facing.
Using namedtuple objects over regular (unstructured) tuples and dicts can as well brand your coworkers' lives easier by making the data that's existence passed around cocky-documenting, at least to a caste:
>>>
>>> from collections import namedtuple >>> Machine = namedtuple ( "Car" , "color mileage automatic" ) >>> car1 = Car ( "red" , 3812.four , True ) >>> # Instances have a nice repr: >>> car1 Car(color="ruby", mileage=3812.4, automated=True) >>> # Accessing fields: >>> car1 . mileage 3812.4 >>> # Fields are immtuable: >>> car1 . mileage = 12 Traceback (most recent call concluding): File "<stdin>", line i, in <module> AttributeError: can't set attribute >>> car1 . windshield = "broken" Traceback (nearly recent phone call last): File "<stdin>", line ane, in <module> AttributeError: 'Car' object has no attribute 'windshield' typing.NamedTuple: Improved Namedtuples
Added in Python 3.half-dozen, typing.NamedTuple is the younger sibling of the namedtuple class in the collections module. It's very similar to namedtuple, with the main deviation being an updated syntax for defining new tape types and added support for type hints.
Please note that type annotations are non enforced without a separate blazon-checking tool like mypy. But fifty-fifty without tool support, they can provide useful hints for other programmers (or exist terribly confusing if the type hints get out of date):
>>>
>>> from typing import NamedTuple >>> class Car ( NamedTuple ): ... colour : str ... mileage : float ... automatic : bool >>> car1 = Motorcar ( "scarlet" , 3812.4 , True ) >>> # Instances have a nice repr: >>> car1 Car(color='red', mileage=3812.4, automatic=Truthful) >>> # Accessing fields: >>> car1 . mileage 3812.4 >>> # Fields are immutable: >>> car1 . mileage = 12 Traceback (near recent call last): File "<stdin>", line 1, in <module> AttributeError: can't set attribute >>> car1 . windshield = "broken" Traceback (well-nigh recent call last): File "<stdin>", line i, in <module> AttributeError: 'Car' object has no attribute 'windshield' >>> # Type annotations are not enforced without >>> # a separate type checking tool similar mypy: >>> Auto ( "red" , "NOT_A_FLOAT" , 99 ) Automobile(color='red', mileage='NOT_A_FLOAT', automated=99) struct.Struct: Serialized C Structs
The struct.Struct class converts between Python values and C structs serialized into Python bytes objects. For example, it tin be used to handle binary data stored in files or coming in from network connections.
Structs are defined using a mini language based on format strings that allows you to define the arrangement of various C data types like char, int, and long as well as their unsigned variants.
Serialized structs are seldom used to represent data objects meant to exist handled purely inside Python code. They're intended primarily as a data substitution format rather than every bit a way of holding information in memory that's only used by Python code.
In some cases, packing primitive data into structs may utilize less memory than keeping information technology in other data types. Still, in most cases that would be quite an advanced (and probably unnecessary) optimization:
>>>
>>> from struct import Struct >>> MyStruct = Struct ( "i?f" ) >>> information = MyStruct . pack ( 23 , Faux , 42.0 ) >>> # All you get is a hulk of data: >>> data b'\x17\x00\x00\x00\x00\x00\x00\x00\x00\x00(B' >>> # Data blobs can exist unpacked again: >>> MyStruct . unpack ( information ) (23, False, 42.0) types.SimpleNamespace: Fancy Attribute Access
Hither's one more than slightly obscure choice for implementing data objects in Python: types.SimpleNamespace. This class was added in Python iii.3 and provides attribute admission to its namespace.
This ways SimpleNamespace instances expose all of their keys as class attributes. You can utilize obj.cardinal dotted aspect access instead of the obj['key'] square-bracket indexing syntax that'due south used by regular dicts. All instances too include a meaningful __repr__ by default.
As its proper name proclaims, SimpleNamespace is uncomplicated! It'due south basically a dictionary that allows aspect access and prints nicely. Attributes tin can exist added, modified, and deleted freely:
>>>
>>> from types import SimpleNamespace >>> car1 = SimpleNamespace ( color = "carmine" , mileage = 3812.four , automatic = True ) >>> # The default repr: >>> car1 namespace(automatic=True, colour='cherry', mileage=3812.4) >>> # Instances support attribute access and are mutable: >>> car1 . mileage = 12 >>> car1 . windshield = "cleaved" >>> del car1 . automatic >>> car1 namespace(color='scarlet', mileage=12, windshield='broken') Records, Structs, and Data Objects in Python: Summary
As you've seen, in that location's quite a number of different options for implementing records or information objects. Which blazon should you employ for data objects in Python? Generally your decision volition depend on your apply case:
-
If you take merely a few fields, then using a plain tuple object may be okay if the field order is easy to call back or field names are superfluous. For example, recollect of an
(x, y, z)point in three-dimensional space. -
If yous need immutable fields, and then plain tuples,
collections.namedtuple, andtyping.NamedTupleare all skilful options. -
If y'all need to lock down field names to avoid typos, then
collections.namedtupleandtyping.NamedTupleare your friends. -
If you desire to keep things unproblematic, then a patently dictionary object might exist a skillful pick due to the user-friendly syntax that closely resembles JSON.
-
If you demand full control over your information construction, then it's time to write a custom grade with
@propertysetters and getters. -
If y'all need to add behavior (methods) to the object, then you should write a custom grade, either from scratch, or using the
dataclassdecorator, or by extendingcollections.namedtupleortyping.NamedTuple. -
If you demand to pack data tightly to serialize information technology to disk or to send it over the network, then it's fourth dimension to read upward on
struct.Structbecause this is a great utilise case for it!
If yous're looking for a safe default choice, then my full general recommendation for implementing a plain tape, struct, or data object in Python would exist to use collections.namedtuple in Python two.10 and its younger sibling, typing.NamedTuple in Python 3.
Sets and Multisets
In this section, you'll see how to implement mutable and immutable set and multiset (bag) data structures in Python using congenital-in data types and classes from the standard library.
A set is an unordered collection of objects that doesn't allow duplicate elements. Typically, sets are used to quickly test a value for membership in the set up, to insert or delete new values from a gear up, and to compute the union or intersection of two sets.
In a proper set implementation, membership tests are expected to run in fast O(1) time. Wedlock, intersection, difference, and subset operations should take O(n) fourth dimension on average. The set up implementations included in Python's standard library follow these performance characteristics.
Just like dictionaries, sets become special treatment in Python and have some syntactic sugar that makes them easy to create. For instance, the curly-brace set up expression syntax and set up comprehensions allow you to conveniently define new set instances:
vowels = { "a" , "eastward" , "i" , "o" , "u" } squares = { ten * x for x in range ( 10 )} Simply be careful: To create an empty set you lot'll need to call the ready() constructor. Using empty curly-braces ({}) is ambiguous and will create an empty dictionary instead.
Python and its standard library provide several fix implementations. Let's have a look at them.
ready: Your Go-To Ready
The set type is the congenital-in prepare implementation in Python. Information technology'southward mutable and allows for the dynamic insertion and deletion of elements.
Python'due south sets are backed past the dict data type and share the aforementioned functioning characteristics. Any hashable object can exist stored in a set:
>>>
>>> vowels = { "a" , "e" , "i" , "o" , "u" } >>> "e" in vowels True >>> letters = set ( "alice" ) >>> letters . intersection ( vowels ) {'a', 'e', 'i'} >>> vowels . add ( "x" ) >>> vowels {'i', 'a', 'u', 'o', 'x', 'east'} >>> len ( vowels ) 6 frozenset: Immutable Sets
The frozenset class implements an immutable version of set that tin't be changed after it's been constructed.
frozenset objects are static and allow only query operations on their elements, not inserts or deletions. Because frozenset objects are static and hashable, they can be used as dictionary keys or as elements of another gear up, something that isn't possible with regular (mutable) fix objects:
>>>
>>> vowels = frozenset ({ "a" , "e" , "i" , "o" , "u" }) >>> vowels . add ( "p" ) Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'frozenset' object has no aspect 'add' >>> # Frozensets are hashable and can >>> # be used as dictionary keys: >>> d = { frozenset ({ one , two , 3 }): "hello" } >>> d [ frozenset ({ 1 , 2 , 3 })] 'hello' collections.Counter: Multisets
The collections.Counter form in the Python standard library implements a multiset, or bag, type that allows elements in the gear up to have more than one occurrence.
This is useful if you demand to go along track of non but if an element is part of a ready, but also how many times information technology's included in the set:
>>>
>>> from collections import Counter >>> inventory = Counter () >>> loot = { "sword" : 1 , "bread" : 3 } >>> inventory . update ( loot ) >>> inventory Counter({'bread': 3, 'sword': 1}) >>> more_loot = { "sword" : i , "apple" : one } >>> inventory . update ( more_loot ) >>> inventory Counter({'bread': three, 'sword': ii, 'apple': 1}) One caveat for the Counter class is that you'll want to be careful when counting the number of elements in a Counter object. Calling len() returns the number of unique elements in the multiset, whereas the total number of elements can be retrieved using sum():
>>>
>>> len ( inventory ) 3 # Unique elements >>> sum ( inventory . values ()) 6 # Full no. of elements Sets and Multisets in Python: Summary
Sets are another useful and commonly used information structure included with Python and its standard library. Here are a few guidelines for deciding which one to utilise:
- If y'all need a mutable ready, then use the born
fixtype. - If you demand hashable objects that can exist used as dictionary or fix keys, then use a
frozenset. - If you need a multiset, or bag, data structure, and so employ
collections.Counter.
Stacks (LIFOs)
A stack is a collection of objects that supports fast Final-In/First-Out (LIFO) semantics for inserts and deletes. Different lists or arrays, stacks typically don't allow for random admission to the objects they contain. The insert and delete operations are also often called push and pop.
A useful real-world analogy for a stack data structure is a stack of plates. New plates are added to the top of the stack, and because the plates are precious and heavy, only the topmost plate tin can be moved. In other words, the concluding plate on the stack must be the get-go i removed (LIFO). To reach the plates that are lower down in the stack, the topmost plates must be removed 1 by 1.
Performance-wise, a proper stack implementation is expected to take O(1) fourth dimension for insert and delete operations.
Stacks accept a wide range of uses in algorithms. For example, they're used in language parsing as well as runtime memory management, which relies on a call stack. A brusk and cute algorithm using a stack is depth-first search (DFS) on a tree or graph data construction.
Python ships with several stack implementations that each have slightly different characteristics. Permit's accept a look at them and compare their characteristics.
list: Elementary, Congenital-In Stacks
Python's built-in list type makes a decent stack data structure as information technology supports push and pop operations in amortized O(1) time.
Python's lists are implemented as dynamic arrays internally, which means they occasionally demand to resize the storage space for elements stored in them when elements are added or removed. The list over-allocates its bankroll storage and so that not every button or popular requires resizing. Every bit a result, you get an amortized O(1) time complexity for these operations.
The downside is that this makes their performance less consistent than the stable O(1) inserts and deletes provided by a linked list–based implementation (as you'll encounter below with collections.deque). On the other manus, lists do provide fast O(1) time random access to elements on the stack, and this can be an added do good.
There'south an important performance caveat that you should be aware of when using lists as stacks: To go the amortized O(1) operation for inserts and deletes, new items must be added to the end of the list with the append() method and removed once again from the end using pop(). For optimum performance, stacks based on Python lists should abound towards higher indexes and shrink towards lower ones.
Adding and removing from the front is much slower and takes O(due north) time, as the existing elements must be shifted around to make room for the new element. This is a functioning antipattern that you should avoid as much as possible:
>>>
>>> s = [] >>> s . suspend ( "eat" ) >>> south . suspend ( "sleep" ) >>> s . append ( "code" ) >>> s ['eat', 'sleep', 'code'] >>> due south . pop () 'code' >>> due south . pop () 'slumber' >>> s . pop () 'eat' >>> s . pop () Traceback (near recent call final): File "<stdin>", line ane, in <module> IndexError: pop from empty list collections.deque: Fast and Robust Stacks
The deque class implements a double-concluded queue that supports adding and removing elements from either finish in O(1) time (non-amortized). Because deques back up adding and removing elements from either terminate equally well, they can serve both every bit queues and equally stacks.
Python's deque objects are implemented as doubly-linked lists, which gives them excellent and consistent operation for inserting and deleting elements but poor O(northward) functioning for randomly accessing elements in the middle of a stack.
Overall, collections.deque is a dandy choice if you lot're looking for a stack information construction in Python'due south standard library that has the performance characteristics of a linked-list implementation:
>>>
>>> from collections import deque >>> s = deque () >>> s . append ( "swallow" ) >>> due south . append ( "slumber" ) >>> southward . append ( "code" ) >>> due south deque(['eat', 'sleep', 'code']) >>> southward . popular () 'code' >>> s . pop () 'sleep' >>> s . pop () 'eat' >>> due south . popular () Traceback (most recent telephone call last): File "<stdin>", line 1, in <module> IndexError: pop from an empty deque queue.LifoQueue: Locking Semantics for Parallel Computing
The LifoQueue stack implementation in the Python standard library is synchronized and provides locking semantics to support multiple concurrent producers and consumers.
Besides LifoQueue, the queue module contains several other classes that implement multi-producer, multi-consumer queues that are useful for parallel calculating.
Depending on your apply instance, the locking semantics might be helpful, or they might merely incur unneeded overhead. In this case, you'd exist better off using a listing or a deque as a general-purpose stack:
>>>
>>> from queue import LifoQueue >>> s = LifoQueue () >>> s . put ( "consume" ) >>> s . put ( "sleep" ) >>> south . put ( "lawmaking" ) >>> s <queue.LifoQueue object at 0x108298dd8> >>> s . get () 'code' >>> s . get () 'sleep' >>> s . get () 'eat' >>> s . get_nowait () queue.Empty >>> s . get () # Blocks/waits forever... Stack Implementations in Python: Summary
As you've seen, Python ships with several implementations for a stack data structure. All of them have slightly different characteristics every bit well as performance and usage trade-offs.
If you're not looking for parallel processing support (or if you don't desire to handle locking and unlocking manually), so your choice comes down to the built-in list type or collections.deque. The deviation lies in the data structure used behind the scenes and overall ease of use.
list is backed by a dynamic assortment, which makes it great for fast random access just requires occasional resizing when elements are added or removed.
The list over-allocates its bankroll storage so that not every button or pop requires resizing, and you get an amortized O(1) time complexity for these operations. But yous exercise need to exist careful to simply insert and remove items using append() and pop(). Otherwise, performance slows down to O(n).
collections.deque is backed by a doubly-linked list, which optimizes appends and deletes at both ends and provides consistent O(1) performance for these operations. Non simply is its functioning more stable, the deque form is too easier to use considering you don't have to worry about adding or removing items from the wrong terminate.
In summary, collections.deque is an excellent selection for implementing a stack (LIFO queue) in Python.
Queues (FIFOs)
In this section, y'all'll see how to implement a First-In/First-Out (FIFO) queue information structure using simply built-in data types and classes from the Python standard library.
A queue is a collection of objects that supports fast FIFO semantics for inserts and deletes. The insert and delete operations are sometimes chosen enqueue and dequeue. Unlike lists or arrays, queues typically don't permit for random access to the objects they contain.
Here's a real-world analogy for a FIFO queue:
Imagine a line of Pythonistas waiting to pick upwardly their conference badges on day one of PyCon registration. Every bit new people enter the briefing venue and queue up to receive their badges, they join the line (enqueue) at the back of the queue. Developers receive their badges and conference swag bags and then go out the line (dequeue) at the front of the queue.
Another way to memorize the characteristics of a queue data construction is to think of it as a pipe. You add ping-pong assurance to 1 end, and they travel to the other end, where you remove them. While the balls are in the queue (a solid metallic piping) you can't get at them. The only style to interact with the assurance in the queue is to add together new ones at the back of the pipage (enqueue) or to remove them at the front (dequeue).
Queues are similar to stacks. The departure betwixt them lies in how items are removed. With a queue, you remove the particular least recently added (FIFO) but with a stack, you lot remove the detail most recently added (LIFO).
Functioning-wise, a proper queue implementation is expected to take O(1) time for insert and delete operations. These are the 2 principal operations performed on a queue, and in a correct implementation, they should be fast.
Queues have a broad range of applications in algorithms and frequently aid solve scheduling and parallel programming problems. A curt and beautiful algorithm using a queue is breadth-first search (BFS) on a tree or graph data structure.
Scheduling algorithms often use priority queues internally. These are specialized queues. Instead of retrieving the next element past insertion fourth dimension, a priority queue retrieves the highest-priority element. The priority of private elements is decided past the queue based on the ordering applied to their keys.
A regular queue, nevertheless, won't reorder the items it carries. Just like in the pipe example, you go out what you put in, and in exactly that order.
Python ships with several queue implementations that each have slightly different characteristics. Let'due south review them.
list: Terribly Sloooow Queues
Information technology's possible to utilise a regular list as a queue, but this is not ideal from a performance perspective. Lists are quite slow for this purpose because inserting or deleting an element at the beginning requires shifting all the other elements by i, requiring O(due north) fourth dimension.
Therefore, I would not recommend using a listing as a makeshift queue in Python unless you're dealing with but a small-scale number of elements:
>>>
>>> q = [] >>> q . append ( "eat" ) >>> q . append ( "slumber" ) >>> q . suspend ( "code" ) >>> q ['eat', 'sleep', 'code'] >>> # Conscientious: This is slow! >>> q . pop ( 0 ) 'consume' collections.deque: Fast and Robust Queues
The deque class implements a double-ended queue that supports adding and removing elements from either stop in O(ane) time (non-amortized). Because deques support adding and removing elements from either end equally well, they tin serve both as queues and as stacks.
Python's deque objects are implemented as doubly-linked lists. This gives them excellent and consistent operation for inserting and deleting elements, but poor O(north) performance for randomly accessing elements in the center of the stack.
As a result, collections.deque is a great default choice if you're looking for a queue data structure in Python's standard library:
>>>
>>> from collections import deque >>> q = deque () >>> q . append ( "eat" ) >>> q . append ( "slumber" ) >>> q . append ( "code" ) >>> q deque(['eat', 'slumber', 'lawmaking']) >>> q . popleft () 'eat' >>> q . popleft () 'sleep' >>> q . popleft () 'lawmaking' >>> q . popleft () Traceback (most recent call concluding): File "<stdin>", line 1, in <module> IndexError: pop from an empty deque queue.Queue: Locking Semantics for Parallel Computing
The queue.Queue implementation in the Python standard library is synchronized and provides locking semantics to back up multiple concurrent producers and consumers.
The queue module contains several other classes implementing multi-producer, multi-consumer queues that are useful for parallel computing.
Depending on your utilize case, the locking semantics might be helpful or but incur unneeded overhead. In this example, y'all'd be amend off using collections.deque as a general-purpose queue:
>>>
>>> from queue import Queue >>> q = Queue () >>> q . put ( "eat" ) >>> q . put ( "sleep" ) >>> q . put ( "code" ) >>> q <queue.Queue object at 0x1070f5b38> >>> q . get () 'eat' >>> q . get () 'sleep' >>> q . become () 'code' >>> q . get_nowait () queue.Empty >>> q . get () # Blocks/waits forever... Queues in Python: Summary
Python includes several queue implementations every bit office of the core language and its standard library.
list objects can be used every bit queues, simply this is mostly not recommended due to deadening functioning.
If y'all're non looking for parallel processing support, and then the implementation offered past collections.deque is an excellent default choice for implementing a FIFO queue information construction in Python. It provides the performance characteristics y'all'd expect from a proficient queue implementation and tin can also be used equally a stack (LIFO queue).
Priority Queues
A priority queue is a container information structure that manages a prepare of records with totally-ordered keys to provide quick access to the record with the smallest or largest key in the fix.
Yous tin think of a priority queue every bit a modified queue. Instead of retrieving the side by side element by insertion time, information technology retrieves the highest-priority element. The priority of individual elements is decided by the order applied to their keys.
Priority queues are normally used for dealing with scheduling bug. For example, you might use them to give precedence to tasks with higher urgency.
Call up about the task of an operating arrangement task scheduler:
Ideally, higher-priority tasks on the system (such equally playing a existent-time game) should accept precedence over lower-priority tasks (such equally downloading updates in the background). By organizing pending tasks in a priority queue that uses task urgency as the key, the task scheduler can quickly select the highest-priority tasks and permit them to run kickoff.
In this department, y'all'll run across a few options for how yous can implement priority queues in Python using congenital-in data structures or data structures included in Python's standard library. Each implementation volition have its own upsides and downsides, merely in my listen in that location's a articulate winner for most common scenarios. Let's observe out which i information technology is.
list: Manually Sorted Queues
Y'all can use a sorted listing to apace identify and delete the smallest or largest element. The downside is that inserting new elements into a list is a ho-hum O(due north) operation.
While the insertion point can exist constitute in O(log n) time using bisect.insort in the standard library, this is always dominated by the irksome insertion pace.
Maintaining the order by appending to the list and re-sorting as well takes at least O(northward log n) fourth dimension. Another downside is that you must manually accept care of re-sorting the list when new elements are inserted. It's easy to introduce bugs by missing this pace, and the brunt is always on yous, the programmer.
This means sorted lists are only suitable as priority queues when there will be few insertions:
>>>
>>> q = [] >>> q . append (( 2 , "code" )) >>> q . append (( 1 , "eat" )) >>> q . append (( three , "sleep" )) >>> # Remember to re-sort every time a new element is inserted, >>> # or use bisect.insort() >>> q . sort ( opposite = True ) >>> while q : ... next_item = q . pop () ... impress ( next_item ) ... (one, 'eat') (ii, 'code') (three, 'sleep') heapq: List-Based Binary Heaps
heapq is a binary heap implementation usually backed by a plain listing, and it supports insertion and extraction of the smallest chemical element in O(log n) time.
This module is a good choice for implementing priority queues in Python. Since heapq technically provides only a min-heap implementation, extra steps must exist taken to ensure sort stability and other features typically expected from a practical priority queue:
>>>
>>> import heapq >>> q = [] >>> heapq . heappush ( q , ( 2 , "code" )) >>> heapq . heappush ( q , ( 1 , "eat" )) >>> heapq . heappush ( q , ( 3 , "slumber" )) >>> while q : ... next_item = heapq . heappop ( q ) ... print ( next_item ) ... (1, 'consume') (two, 'code') (three, 'sleep') queue.PriorityQueue: Cute Priority Queues
queue.PriorityQueue uses heapq internally and shares the same time and infinite complexities. The difference is that PriorityQueue is synchronized and provides locking semantics to back up multiple concurrent producers and consumers.
Depending on your use case, this might be helpful, or information technology might just tiresome your program downwards slightly. In any case, you might adopt the class-based interface provided past PriorityQueue over the role-based interface provided by heapq:
>>>
>>> from queue import PriorityQueue >>> q = PriorityQueue () >>> q . put (( 2 , "code" )) >>> q . put (( 1 , "eat" )) >>> q . put (( 3 , "slumber" )) >>> while not q . empty (): ... next_item = q . get () ... print ( next_item ) ... (1, 'eat') (ii, 'code') (3, 'sleep') Priority Queues in Python: Summary
Python includes several priority queue implementations prepare for you lot to use.
queue.PriorityQueue stands out from the pack with a dainty object-oriented interface and a proper noun that conspicuously states its intent. It should be your preferred pick.
If you'd like to avoid the locking overhead of queue.PriorityQueue, then using the heapq module directly is likewise a skillful option.
Conclusion: Python Data Structures
That concludes your tour of common data structures in Python. With the cognition you've gained here, yous're ready to implement efficient data structures that are just right for your specific algorithm or use case.
In this tutorial, you've learned:
- Which common abstruse data types are built into the Python standard library
- How the virtually common abstract data types map to Python's naming scheme
- How to put abstruse data types to practical apply in various algorithms
If you enjoyed what you lot learned in this sample from Python Tricks, and so exist sure to check out the rest of the book.
If you're interested in brushing upwardly on your general data structures cognition, then I highly recommend Steven S. Skiena'due south The Algorithm Blueprint Transmission. It strikes a great balance betwixt teaching you key (and more than advanced) data structures and showing you how to implement them in your code. Steve'south book was a great assist in the writing of this tutorial.
Source: https://realpython.com/python-data-structures/
0 Response to "Python Script That Reads in the Contents and Stores the Data in a Container"
Post a Comment